Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по
pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.
Нельзя сказать, что это — исчерпывающий список возможностей
pandas, но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
import pandas as pd
import numpy as np
anime = pd.read_csv('anime-recommendations-database/anime.csv')
rating = pd.read_csv('anime-recommendations-database/rating.csv')
anime_modified = anime.set_index('name')
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как
encoding='ISO-8859–1'). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.anime = pd.read_csv('anime-recommendations-database/anime.csv')

Загруженные CSV-данные
Существует похожая функция для загрузки данных из Excel-файлов —
pd.read_excel.▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
df = pd.DataFrame([[1,'Bob', 'Builder'],
[2,'Sally', 'Baker'],
[3,'Scott', 'Candle Stick Maker']],
columns=['id','name', 'occupation'])

Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
anime_copy = anime.copy(deep=True)

Копия датафрейма
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
rating[:10].to_csv('saved_ratings.csv', index=False)
Экспортировать данные в виде Excel-файлов можно с помощью функции
df.to_excel.4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых
n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.anime.head(3)
rating.tail(1)

Данные из начала датафрейма

Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция
len(), которую я тут покажу, не входит в состав pandas. Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.len(df)
#=> 3
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
len(ratings['user_id'].unique())
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
anime.info()

Сведения о датафрейме
Есть ещё одна функция, похожая на
df.info — df.dtypes. Она лишь выводит сведения о типах данных столбцов.▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца
rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:anime.describe()

Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
anime.type.value_counts()

Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные
x и y для обучения модели. Здесь применимы следующие команды:anime['genre'].tolist()
anime['genre']

Результаты работы команды anime['genre'].tolist()

Результаты работы команды anime['genre']
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм
anime_modified, так как его индексные значения выглядят интереснее.anime_modified.index.tolist()

Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
anime.columns.tolist()
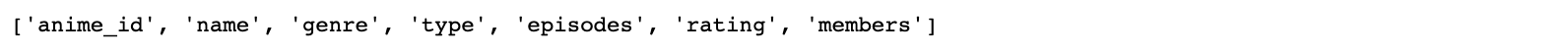
Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
anime['train set'] = True
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
anime[['name','episodes']]

Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
anime.drop(['anime_id', 'genre', 'members'], axis=1).head()

Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция
df.sum(axis=0), которая позволяет получать суммы значений из различных строк. df = pd.DataFrame([[1,'Bob', 8000],
[2,'Sally', 9000],
[3,'Scott', 20]], columns=['id','name', 'power level'])
df.append(df.sum(axis=0), ignore_index=True)

Результат выполнения команды
Команда вида
df.sum(axis=1) позволяет суммировать значения в столбцах.Похожий механизм применим и для расчёта средних значений. Например —
df.mean(axis=0).7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
df1 = anime[0:2]
df2 = anime[2:4]
pd.concat([df1, df2], ignore_index=True)

Датафрейм df1

Датафрейм df2

Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция
df.merge, которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.rating.merge(anime, left_on=’anime_id’, right_on=’anime_id’, suffixes=(‘_left’, ‘_right’))

Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма
anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.anime_modified.loc[['Haikyuu!! Second Season','Gintama']]

Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции
df.iloc первой строке назначается индекс 0, второй — индекс 1, и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.Следующая конструкция позволяет выбрать три первых строки датафрейма:
anime_modified.iloc[0:3]

Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
anime[anime['type'].isin(['TV', 'Movie'])]

Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
anime[anime[‘type’] == 'TV']
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
anime[1:3]

Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
anime[anime['rating'] > 8]

Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией
df.sort_values:anime.sort_values('rating', ascending=False)

Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
anime.groupby('type').count()

Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется
reset_index(). В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.anime.groupby(["type"]).agg({
"rating": "sum",
"episodes": "count",
"name": "last"
}).reset_index()
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
tmp_df = rating.copy()
tmp_df.sort_values('user_id', ascending=True, inplace=True)
tmp_df = tmp_df[tmp_df.user_id < 10]
tmp_df = tmp_df[tmp_df.anime_id < 30]
tmp_df = tmp_df[tmp_df.rating != -1]
pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum, fill_value=0)

Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения
0 в ячейки, содержащие значение NaN. В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0. А затем используем функцию fillna(0) для замены значений NaN на 0.pivot = pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum)
pivot.fillna(0)

Таблица, содержащая значения NaN

Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию
df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1, то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.anime.sample(frac=0.25)

Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
for idx,row in anime[:2].iterrows():
print(idx, row)

Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой
IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:jupyter notebook — NotebookApp.iopub_data_rate_limit=1.0e10
Итоги
Здесь я рассказал о некоторых полезных приёмах использования
pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.Уважаемые читатели! Есть ли какие-нибудь возможности
pandas, без которых вы не представляете своей повседневной работы?Источник - https://habr.com/ru/company/ruvds/blog/494720/

Комментариев нет:
Отправить комментарий